最近ローカルAIの利用を始めました。
AIのモデル、コンテキスト長のバランスを色々探っていたところ、良さそうなものが見つかったのでメモに残しておこうと思います。
※メモのまとめはGeminiに任せました
…では始めます。(Geminiさんお願いします)
自作PC×ローカルLLM環境において、一つの理想的なセッティングに到達したので記録。
1. 検証環境・設定値
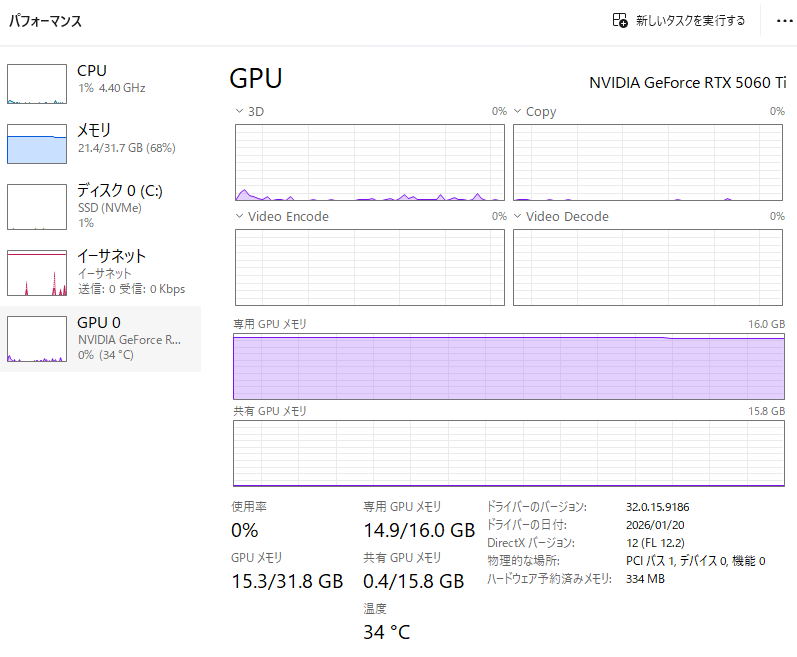
- GPU: NVIDIA GeForce RTX 5060 Ti (VRAM 16GB)
- モデル: gpt-oss-20b(Unsloth最適化版 / Q4_K_M量子化)
- コンテキスト長: 65,536 (64k)
- VRAM使用量: 14.8GB(専用GPUメモリ内)
- 生成速度: 110 tokens/sec(爆速)
2. 「14.8GB」という数値の持つ意味
VRAM 16GBという「器」に対し、システム(Windows)の専有領域を確保しつつ、残りのスペースを限界までAIに割り当てた結果がこの数値。
- オール・イン・VRAM: モデルと記憶のすべてが高速な専用メモリに収まっているため、共有メモリ(RAM)への転送遅延が発生せず、100回/秒を超える生成速度を維持できている。
- 限界チューニング: 15GBを超えると不安定になるリスクがある中、14.8GBは「最も賢く、最も速い」状態を維持できるスイートスポット。
3. 「64k (65536)」のコンテキストでできること
記憶容量が約5万〜6万文字に達したことで、実用性が劇的に向上。
- 長編資料の丸読み: 技術ドキュメントや短編小説を一括で放り込み、矛盾なく対話が可能。
- プロジェクト単位のコード解析: 関連ファイルを複数枚読み込ませた状態でのリファクタリングやバグ取りが「忘却」なしで行える。
- 思考の連続性: 長時間のチャットでも、初期の指示や複雑な設定を維持したまま、110 token/secの速度で回答が返ってくる。
4. 結論:16GB版グラボを選んだのは「正解」だった
8GB版では絶対に到達できない「広大な記憶」と「爆速の推論」の両立。 今後、Qwen3.6-20Bなどの次世代中規模モデルが公開されれば、この14.8GBという枠をさらに高密度な「知能」で埋めることができる。
現状、一般ユーザーがローカルでAIをフル活用するための、一つの**「完成形」**と言えるセッティング。
なお、ブラウザ等を開くと専用GPUが増えるみたいなので注意。(14.9GBになってた)
今後qwenの20B前後のモデルが公開されたら、実用性が増しそうな印象です。
※Qwen3.6-27BはVRAM16GBで扱うには少し重いんだよなあ、もう少し待ちたいところです。